
The Real Bottleneck in Healthcare AI
The constraint holding back healthcare AI is not the algorithm. It is that most clinical data was never structured, governed, or prepared for model training.
By Robert Kelly, Founder & CEO, Heart Rhythm International
Across healthcare, AI projects are accelerating. Funding is flowing. Partnerships are forming. Research timelines are being set. Yet the field is still often discussed as though the main challenge is model performance. It is not.
Quietly, in laboratories and research consortia around the world, teams are reaching for synthetic data.
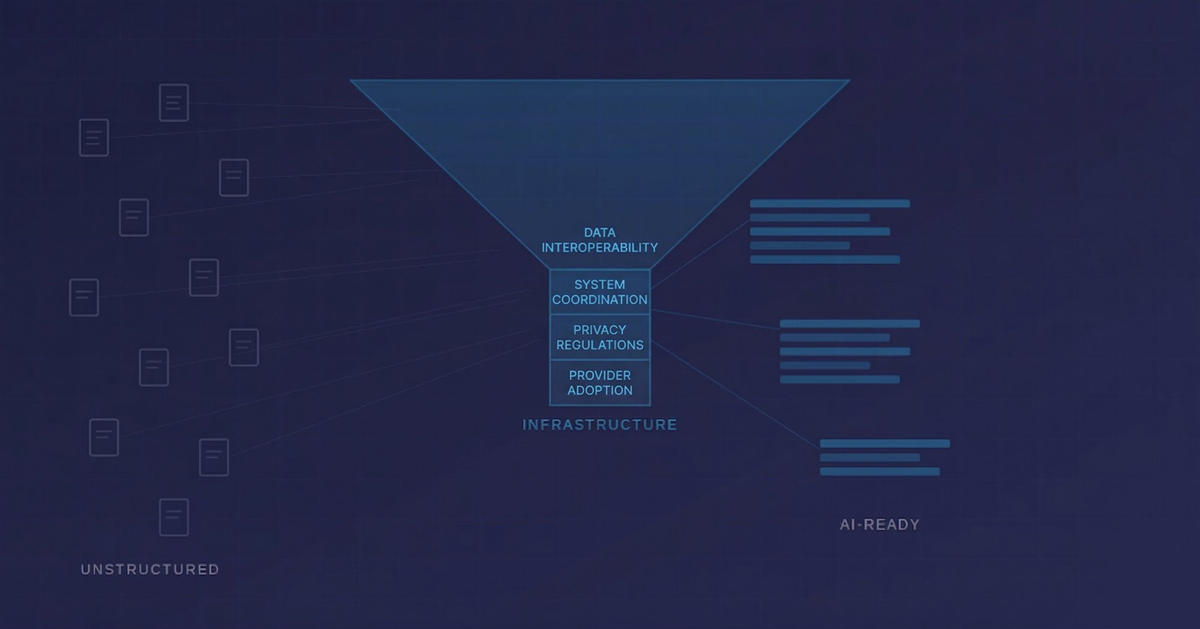
Not because real patient data does not exist. It exists in enormous quantities. But because the data that exists is largely unusable for the purposes of training a clinical AI model. It sits in PDFs. It lives in scanned letters. It is buried in free-text fields that were designed for a clinician to read, not a machine to learn from.
Synthetic data, artificially generated datasets designed to mimic real patient populations, is increasingly being used as a workaround in healthcare AI development, including by major medical device and healthcare technology organisations. The issue is not a lack of data. It is that much of the real-world data they hold was never structured, governed, or prepared for model training.
That is worth pausing on.
The first problem: unstructured data
A senior figure in Irish health policy described it plainly in a recent conversation. The health system, he said, has vast amounts of data. But most of it is sitting in files and PDFs.
This is not a uniquely Irish problem. It is the default condition of health systems that were digitised in a hurry, or digitised piecemeal, or never fully digitised at all. Clinical notes typed into free-text fields. Procedure reports generated as documents. Letters scanned and filed.
The result is an archive, not a dataset.
An archive can tell you that something happened. It cannot tell you what happened, to whom, when, in what sequence, and with what outcome in a form that a model can learn from at scale.
Clinical AI requires data that was captured in structured form at the point of care, consistently, over time, across a population. The gap between what health systems have collected and what AI actually needs is wider than most people in the field are willing to say publicly.
The second problem: consent
Alongside the structural problem sits a legal one that receives even less attention.
Much health data was collected for direct care, not with AI model development explicitly in mind. It did not contemplate the specific uses, the third-party relationships, or the international data flows that modern AI development involves.
The EU AI Act and GDPR are now creating a legal environment where that ambiguity is becoming harder to sustain. Regulators are asking sharper questions about the basis on which data is being used to train models.
Retrofitting consent onto historical datasets is not straightforward. In many cases, it is not possible. Projects built on data with a weak consent foundation are building on ground that may not hold.
What AI-ready data actually looks like
There is an alternative model, but it requires infrastructure that was designed with this in mind from the beginning.
AI-ready health data is structured at the point of capture. Not extracted from documents after the fact, but recorded in discrete, queryable fields as part of the clinical workflow itself. It is governed lawfully and transparently, with appropriate consent or other valid legal basis in place. And it is longitudinal, following the patient across years of care, across institutions, across device changes and procedure types.
That combination, structured, governed, and longitudinal, is what separates data that can support regulatory-grade AI deployment from data that can only support research publication.
The CARAMEL project, funded under Horizon Europe, is developing AI-supported models for women's cardiovascular health, with Irish partners contributing cardiovascular data and domain expertise. That work depends on infrastructure and datasets that already exist within the participating ecosystem.
The regulatory bar is rising
The EU AI Act and Medical Device Regulation are setting a bar that AI projects in healthcare will need to clear before deployment at scale.
That bar requires traceability, auditability, and evidence that the data used to train a model was collected lawfully, structured consistently, and governed appropriately. It requires that models can be validated against real-world outcomes, not just research datasets.
Many current healthcare AI projects may struggle to meet that bar in full. Not because the models are poorly designed, but because the data underneath them was never built to support this level of scrutiny.
The regulatory environment is not slowing down. It is the direction of travel.
Infrastructure before intelligence
The global conversation about healthcare AI is focused on the wrong layer.
Model performance and benchmark results dominate the discussion. The harder question, what the data infrastructure underneath these models actually looks like, is not being asked loudly enough.
Organisations that recognised this early, that built infrastructure designed for continuous clinical use rather than retrospective reporting, are now in a position that cannot easily be replicated. Structured, governed, longitudinal data does not appear overnight. It is the product of years of deliberate design and consistent clinical workflow.
Without it, healthcare AI will remain stronger in demonstration than in deployment.
The bottleneck is not the algorithm.
It never was.



